About This Project
Team Members
- Nicolas Botello
- Yang Yang
- Austin Tang
- Connor Flatt
Class
Texas A&M University CSCE 489 with Dr. Caverlee
Overview and Motivation
Have you ever wondered if a picture could say a thousand words? Or have you ever wondered if a picture has any influence on how we make decisions?
These are questions the GIT -REKT team pondered on in the beginning of the “recommend me, senpai” project. The team received a dataset on “myanimelist.com” from a fellow researcher. The dataset holds a massive amount of data containing reviews from users and anime image links. In addition, we found a great library called illustration2vec that analyzes anime images and gives back labels to the images sent to the library. With this data and illustration2vec we could, find answers to the initial questions asked at the beginning of our analysis.
Since we had anime photos and a library to analyze them with, we decided to give a more focused question compared to our initial questions.
The main question we decided to solve was, can we judge a video by it’s cover?
Observations
While loading in a total of 13k pictures that contained an average of 4 labels per picture that were over the 50% likelihood of being on it. we found the following:
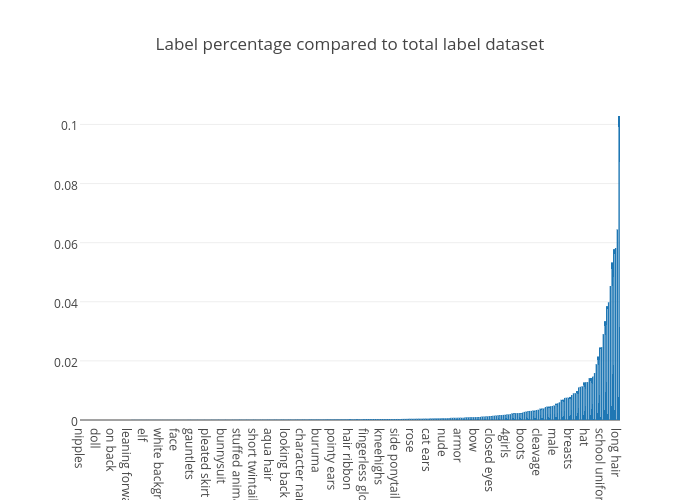
We saw that there was a huge gap between everything that came out 1% and lower so we decided to look further into that space.
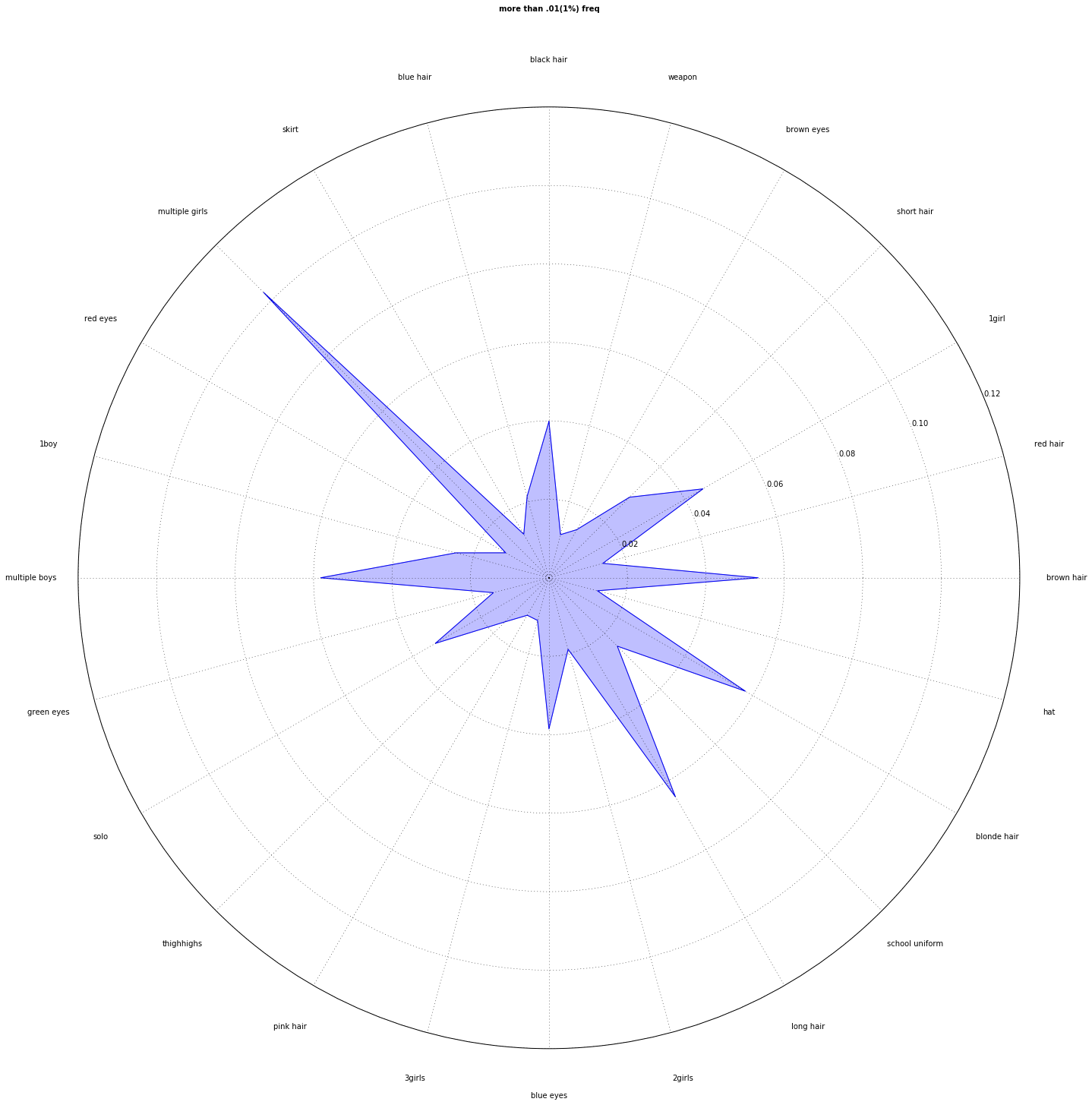
We found that these tags didn't have any true value to recommend the anime. So we removed them from the data set while increasing our prediction scores.
Classification
We decided to use two different classifiers. Naive bayes and random forest. We found out that taking out any labels that are above a 1% frequency improved our test scores. In addition, both classifiers gave around the same prediction scores. From our 64% average test score , we can conclude that with our current model, we cannot accurately predict if a person would like an anime based on its video cover. Since our scores were low, we decided that our labels were not meaningful separately. This lead us to group our labels to believe that if we grouped similar labels, we could increase the prediction.
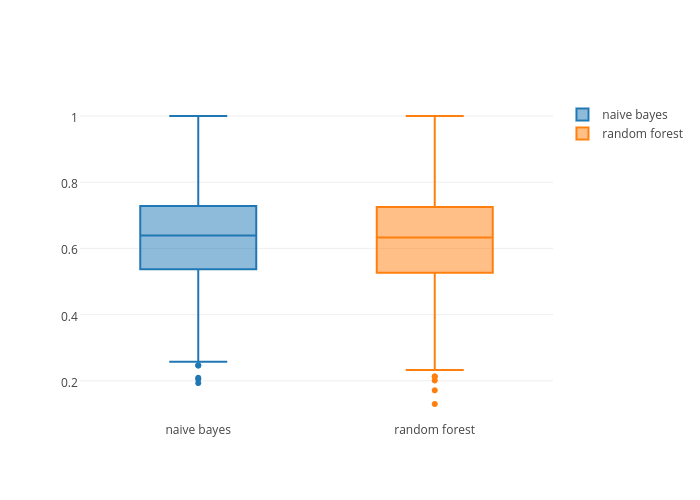
GENRE BASED CLASSIFICATION
Rather than running our labels alone , we found that that if we could predict the genre of the labels, we could get a better prediction score of 68%. If we use our labels and genres, the prediciton score is around 66%.
Conclusion
Can we judge a video by its cover? No, but our feature based recommendation system does looks promising for the future.
Humans have a very big discrepancy in terms of what they watch, we believe this threw off the binary classification for predicting what the people liked. However, the i2v label generator gave us useful labels such as gun,military uniform, and musical note. Most of the time the labels gave us very descriptive labels of the setting and characters. These descriptive labels weren’t as good at recognizing other features that we believe would be better to predict . However, our genre predictor based on the i2v labels did very well showing over 90% accuracy. In addition, when we used our genre in our feature based recommendation system we found that we get an increase to 68% average predictor score from it's old 64% accuracy.
Future Work
In future work increasing the features and labels for each photo by using additional libraries would be a great help to the accuracy of the algorithm. If we combine this system with more labels, our genre based predictor, and labels taken from collaborative filtering, it has the potential to create an even better recommender structure.